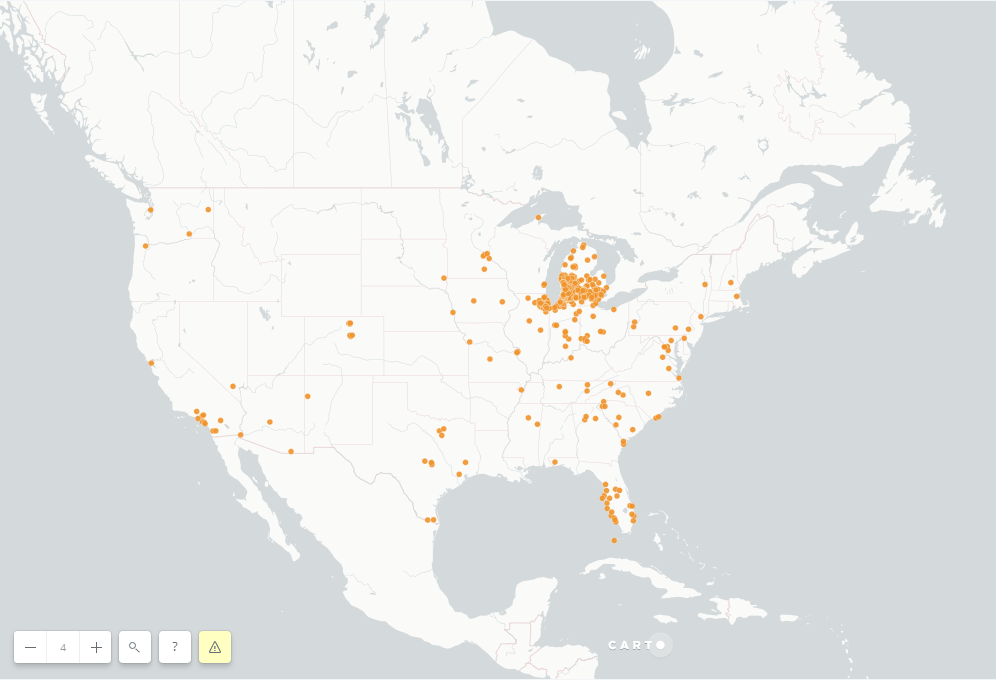
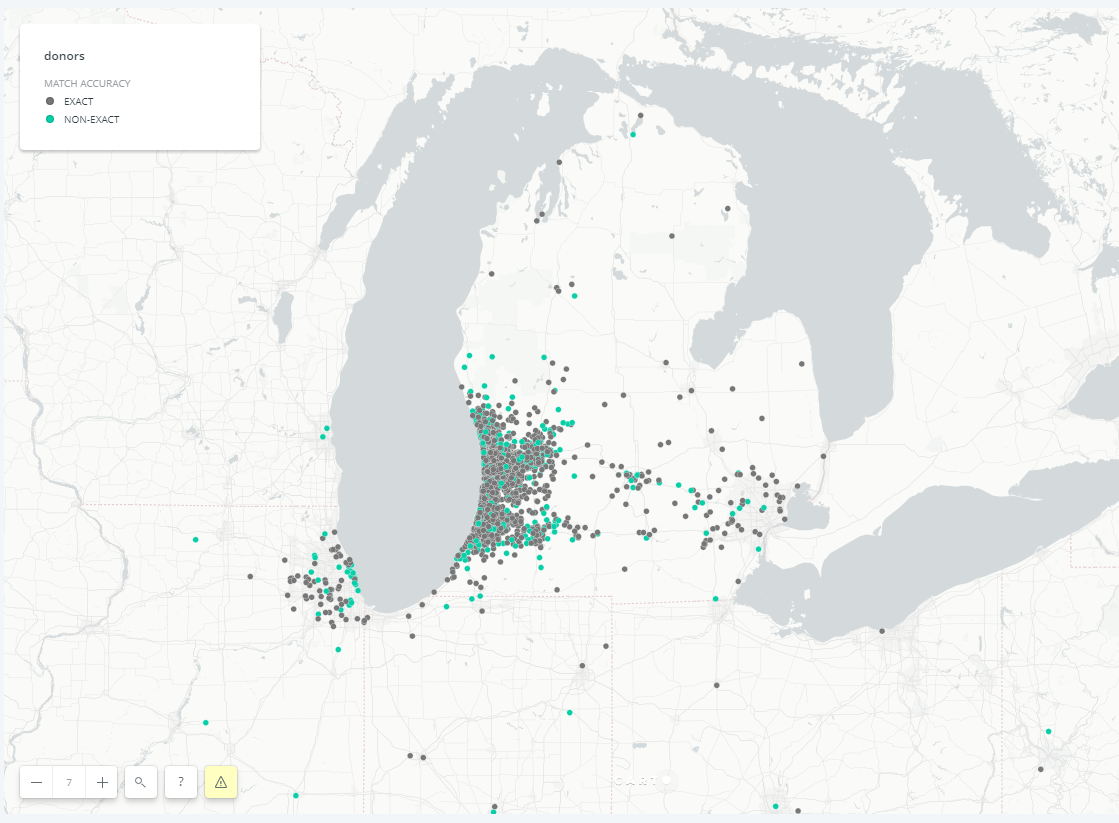
The goal of this project was to map out the donors of a nonprofit in West Michigan. The CSV of donors numbered over 10,000 records. While there are many geocoding options out there, I decided to turn to an organization that specializes in data gathering for residences: the U.S. Census Bureau.
First, I formatted the CSV for geocoding via Python’s pandas library:
The maximum amount the U.S. Census Bureau can geocode per file is 10,000. Since I was working with a CSV that slightly exceeded that, I needed to split the CSV in two. While there is probably a more elegant and flexible way to program this, the following should suffice:
Now that I have files the census geocoder can handle, I can plug it into a function. This function will take the CSV as an input, and it will output a formatted CSV with additional information, such as latitude, longitude, match accuracy and more.
Each function call, which geocodes around 5,000 addresses, takes around an hour and a half.
FORMATTING & RESULTS
There was only one glaring error produced by the API that had to be fixed by hand. If an address had an apartment or suite number, it would put that suite number in an extra cell, thereby ruining the uniformity of the CSV. This was easily fixable by hand.
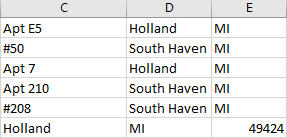
Since I had to check and fix the results by hand, I put the rest of the code into a second script. To reformat all of this data, I concatenated the two CSVs back together:
Out of the 11,016 rows of data: - 9,374 were Matches (85.1%) - 935 were Ties (8.5%) - 703 were No Matches (6.4%)
Out of those matches, 80.4% were exact, and 19.6% were non-exact. Match accuracies hovering around 85% seem to be adequate, though there is always room for improvement. It should be noted that some of the Ties and No Matches are due to some donors not providing data as to where they live. Moreover, this can explain how there are a total of 11,012 results (amongst match, tie, and no-match) from 11,016 rows of data.
The geocoding output produces 14 additional columns to my CSV, four of which I needed: longitude, latitude, match type, and match accuracy. First I dropped superfluous columns, kept the unique ID, and then concatenated the two outputs. The API’s documentation isn’t fantastic, so the meaning of the match type, Tie, is not entirely clear. However, it is clear enough that both Tie and No_Match do not produce coordinates.
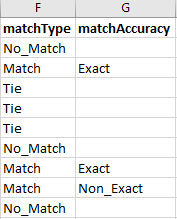
Next I stripped the CSV of any unnecessary data before merging it with the original document. Since the original document is only lacking coordinates and match types, I can drop everything but those four fields (latitude, longitude, match type, and match accuracy). In the next step, I’ll need to merge this output with the original spreadsheet, therefore, values must be ordered based on its index so the spreadsheets will match up.
Now it is ready to merge with the original spreadsheet:
With all data acquired, the spreadsheet just needs to be cleaned up and reformatted.
And with this, the final product can be uploaded to CARTO. The latitude and longitude do not need to be converted to a shapefile; CARTO simply recognizes those columns and converts it to something mappable.